I've been dwelling through RL theory and practice and one particular part I find hard to properly understand is the relation between the practical loss function and the theoretical objective/gradient of the objective. How do we derive one from another? Maybe it is easier with some examples:
Reinforce with baseline:
Theoretical Critic Objective Gradient
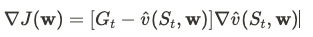
Practical loss (pseudocode) I've come across:
critic_loss = 0.5 * (returns - v_hat(states))**2 Semi gradient SARSA:
Theoretical Objective Gradient
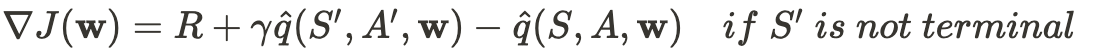
Practical loss (pseudocode) I've come across:
loss = (r + gamma * qvalue(s_next,a_next) - qvalue(s,a)) ** 2 Where are these coming from? Is it the negative inverse of ∇J(w)? If so, could somebody show how it's done? I can only find resources on how to do this for w with fixed dimensions.
I might be completely off here, not getting some foundational property. If that is the case, I would thank deeply if you could direct me to relevant (introductory) literature.