I have a pandas dataframe df1:
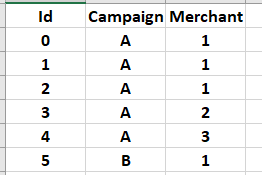
Now, I want to filter the rows in df1 based on unique combinations of (Campaign, Merchant) from another dataframe, df2, which look like this:
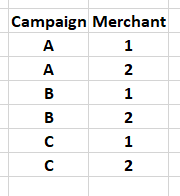
What I tried is using .isin, with a code similar to the one below:
df1.loc[df1['Campaign'].isin(df2['Campaign']) & df1['Merchant'].isin(df2['Merchant'])] The problem here is that the conditions are independent eg : I want to check if (A,1) from df2 is in df1, but with the above condition, since I am checking all the list, not row by row, it would return all rows in df1 where Campaign column is A OR Merchant column is 1.
Do you have any suggestion for this multiple pandas filtering?