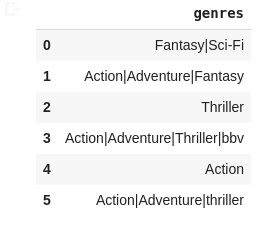
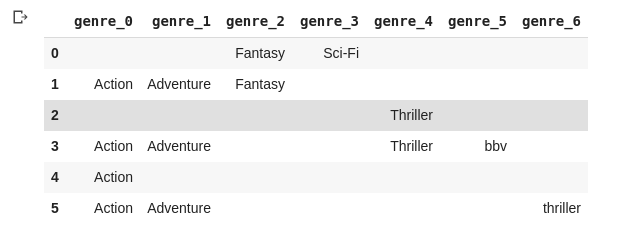
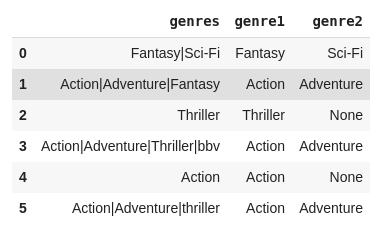
I am working on this CSV file which is a collection of movie details from IMDB. In this I have a genres column in the dataframe with all the genres of the movies seperated by a pipe (|)
What I need is to extract the first two genres from the genres column and store them in two new columns: genre_1 and genre_2.
And for the columns where there is only 1 genre, extract the single genre into both the columns, i.e. for such movies the genre_2 will be the same as genre_1.
I am sharing the screen shots of the code and results that I have got. 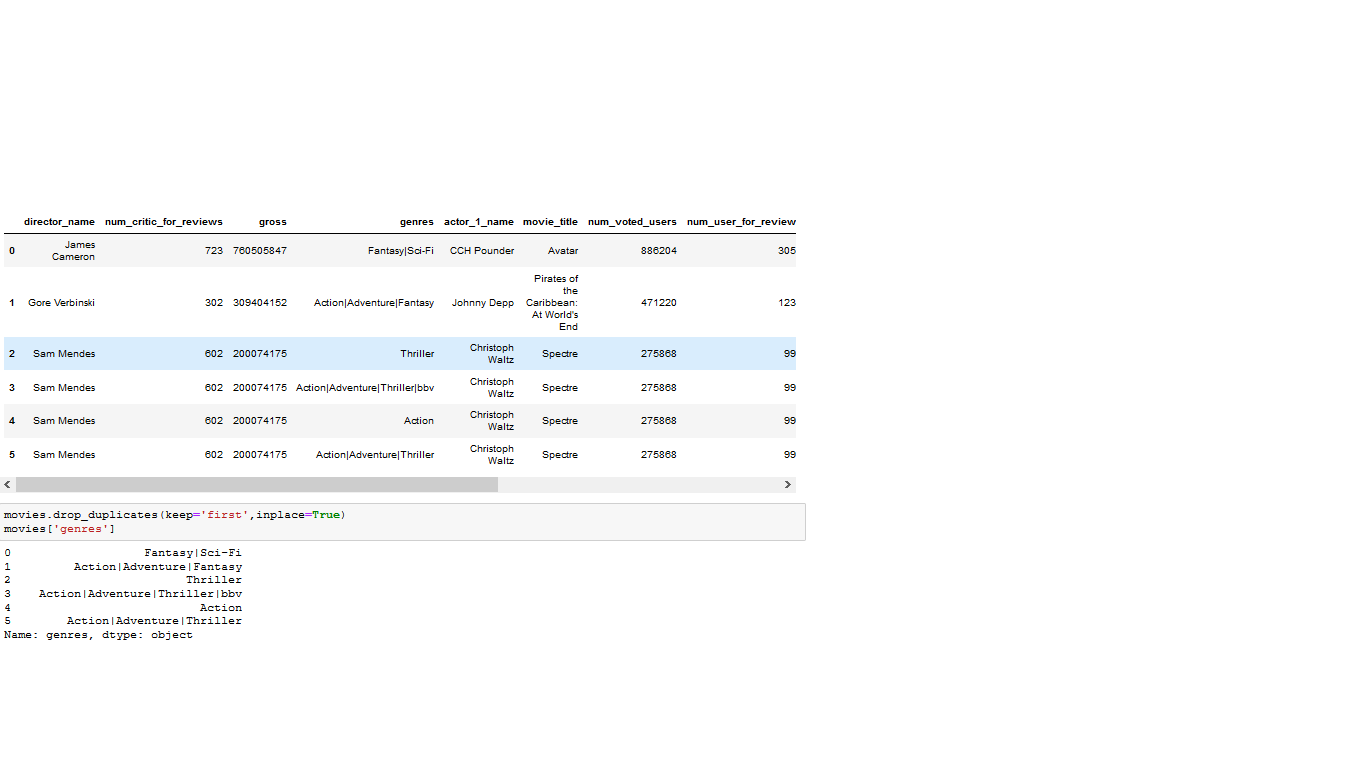
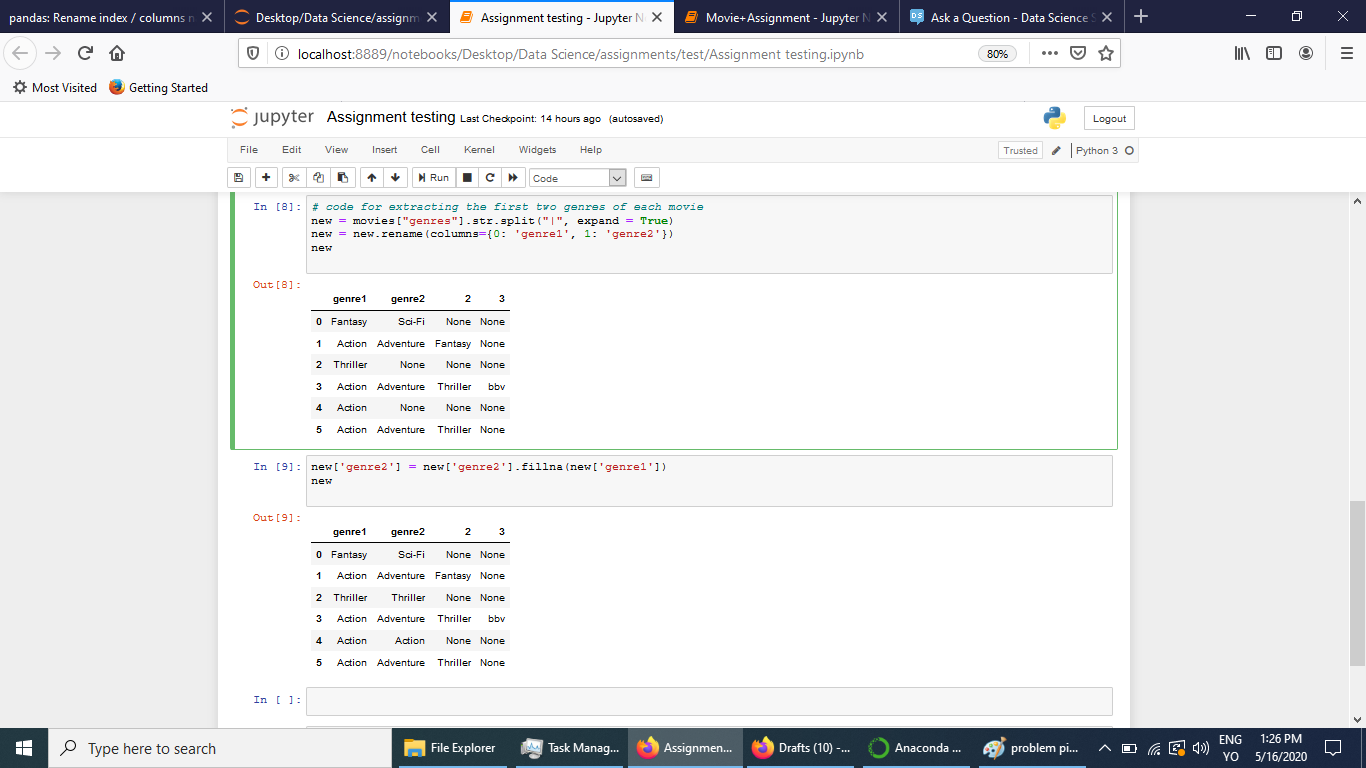
Now, I can create a new data frame with the genres created and can then remove the unwanted columns and can concatenate the remaining the with original data frame. But that looks pretty clumsy.
How can I crate split the column in my original data frame only and remove the unwanted expanded columns.
Any help is appreciated.